在使用 Arduino 的 TFT_eSPI 库时,若需显示中文字符,我们可以通过自定义字库来实现。以下是详细步骤。
字库制作工具位置 🔗
以我的安装目录为例,工具存放在项目根目录的 libraries\TFT_eSPI\Tools\Create_Smooth_Font\Create_font 目录下。
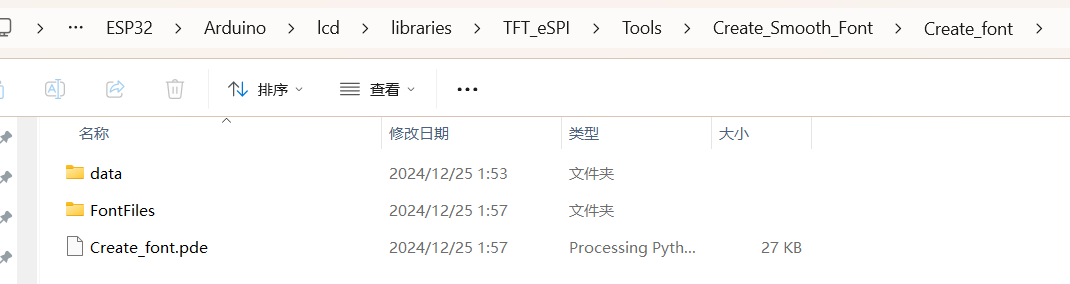
该目录包含以下文件和文件夹:
- data:用于存放字体文件(以
.ttf结尾)。 - FontFiles:用于存放生成的字库文件(以
.vlw结尾)。 - Create_font.pde:生成字库文件的代码。
制作字库的步骤 🔗
第一步:下载字体文件 🔗
下载 钉钉进步体 字体文件(以 .ttf 结尾)。
第二步:安装 Processing 软件 🔗
从 Processing 官网 下载并安装 Processing 软件。
第三步:打开生成脚本 🔗
使用 Processing 软件打开 Create_font.pde 文件。
第四步:复制字体文件 🔗
将下载的字体文件(如 .ttf 格式)复制到 data 目录。
第五步:修改代码 🔗
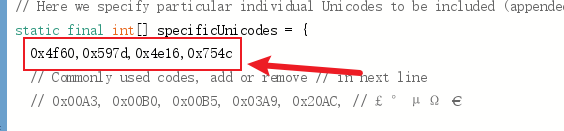
使用Python代码将中文转为Unicode码,在 Create_font.pde 中添加所需的中文字符对应的 Unicode 码,确保需要的字符都包含在字库中。
第六步:运行生成字库 🔗
运行 Create_font.pde 文件,成功后会弹出以下提示:
- 一个图片预览窗口。
- 在
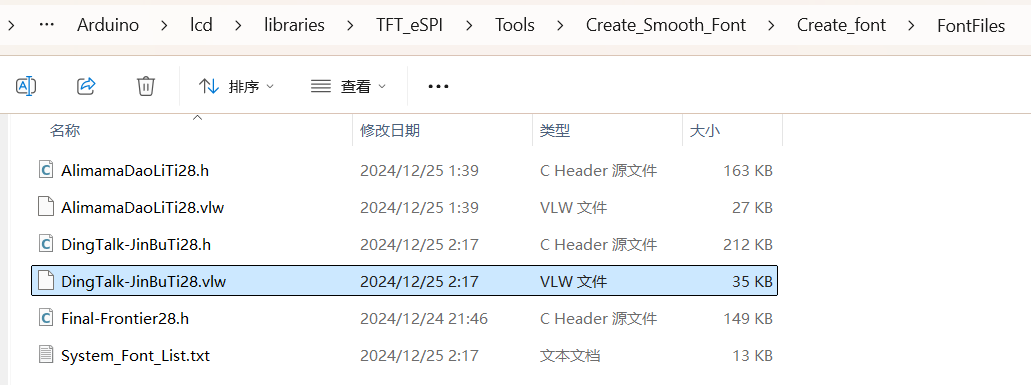
FontFiles目录中生成.vlw字库文件,例如DingTalk-JinBuTi28.vlw。

第七步:转换为 Arduino 字库文件 🔗
- 打开在线工具:File to Hex Converter。
- 上传
.vlw文件(如DingTalk-JinBuTi28.vlw)。 - 将生成的十六进制数据保存为
.h文件(如my_font28.h),供 Arduino 使用。
#include <pgmspace.h>
const uint8_t my_font28[] PROGMEM ={
};
使用自定义字库 🔗
以下是示例代码,展示如何在 Arduino 中加载和使用生成的字体文件:
#include <TFT_eSPI.h>
#include <SPI.h>
#include "my_font28.h" //导入字库文件
#define TFT_GREY 0x5AEB // 定义新颜色:灰色
TFT_eSPI tft = TFT_eSPI(); // 调用库
void setup(void)
{
tft.init(); // 初始化
tft.setRotation(0); // 设置旋转角度为0
tft.invertDisplay(0); // 不反转显示
}
void loop()
{
// 用灰色填充屏幕,以便我们可以看到有背景色和无背景色打印的效果
tft.fillScreen(TFT_GREY);
// 设置字体颜色为绿色,背景色为黑色,文本大小倍数为1
tft.setTextColor(TFT_YELLOW, TFT_BLACK);
tft.loadFont(my_font28); // 指定tft屏幕对象载入my_font28字库
tft.drawString("你好世界", 0, 3);
tft.unloadFont(); // 释放字库文件,节省资源
delay(10000);
}
注意事项 🔗
- Unicode 范围:确保在
Create_font.pde中添加的 Unicode 码覆盖需要显示的所有中文字符。 - 内存占用:大字体文件可能占用较多内存,需注意 ESP32 的内存限制。
- 屏幕兼容性:确保屏幕支持
TFT_eSPI库,且屏幕驱动芯片已在库中正确配置。
完成以上步骤后,即可在 Arduino 项目中顺利使用中文字符。🎉
使用Python将中文转为unicode码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 定义要转换的中文字符串
chinese_str = "你好世界"
# 创建一个空列表来存储转换后的Unicode码点
unicode_codepoints = []
# 创建一个空集合来跟踪已经添加过的字符
seen_chars = set()
# 遍历字符串中的每个字符
for char in chinese_str:
# 如果字符还没有被添加过
if char not in seen_chars:
# 使用ord()函数获取字符的Unicode码点,并使用f-string格式化为0x前缀的十六进制表示
codepoint = f"0x{ord(char):04x}"
# 将格式化后的码点添加到列表中
unicode_codepoints.append(codepoint)
# 将字符添加到已添加过的字符集合中
seen_chars.add(char)
# 将转换后的Unicode码点列表转换为一个字符串,用逗号分隔
codepoints_str = ",".join(unicode_codepoints)
# 打开一个文件来写入数据
with open("unicode_codepoints.txt", "w", encoding="utf-8") as file:
# 将数据写入文件
file.write(codepoints_str)
# 打印一条消息表示数据已经保存
print("Unicode码点已保存到unicode_codepoints.txt文件中。")
print(codepoints_str)
Create_font.pde文件:
// This is a Processing sketch, see https://processing.org/ to download the IDE
// Select the font, size and character ranges in the user configuration section
// of this sketch, which starts at line 120. Instructions start at line 50.
/*
Software License Agreement (FreeBSD License)
Copyright (c) 2018 Bodmer (https://github.com/Bodmer)
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
The views and conclusions contained in the software and documentation are those
of the authors and should not be interpreted as representing official policies,
either expressed or implied, of the FreeBSD Project.
*/
////////////////////////////////////////////////////////////////////////////////////////////////
// This is a processing sketch to create font files for the TFT_eSPI library:
// https://github.com/Bodmer/TFT_eSPI
// Coded by Bodmer January 2018, updated 10/2/19
// Version 0.8
// >>>>>>>>>>>>>>>>>>>> INSTRUCTIONS <<<<<<<<<<<<<<<<<<<<
// See comments below in code for specifying the font parameters (point size,
// unicode blocks to include etc.). Ranges of characters (glyphs) and specific
// individual glyphs can be included in the created "*.vlw" font file.
// Created fonts are saved in the sketches "FontFiles" folder. Press Ctrl+K to
// see that folder location.
// 16-bit Unicode point codes in the range 0x0000 - 0xFFFF are supported.
// Codes 0-31 are control codes such as "tab" and "carraige return" etc.
// and 32 is a "space", these should NOT be included.
// The sketch will convert True Type (a .ttf or .otf file) file stored in the
// sketches "Data" folder as well as your computers' system fonts.
// To maximise rendering performance and the memory consumed only include the characters
// you will use. Characters at the start of the file will render faster than those at
// the end due to the buffering and file seeking overhead.
// The inclusion of "non-existant" characters in a font may give unpredicatable results
// when rendering with the TFT_eSPI library. The Processing sketch window that pops up
// to show the font characters will print "boxes" (also known as Tofu!) for non existant
// characters.
// Once created the files must be loaded into the ESP32 or ESP8266 SPIFFS memory
// using the Arduino IDE plugin detailed here:
// https://github.com/esp8266/arduino-esp8266fs-plugin
// https://github.com/me-no-dev/arduino-esp32fs-plugin
// When the sketch is run it will generate a file called "System_Font_List.txt" in the
// sketch "FontFiles" folder, press Ctrl+K to see it. Open the file in a text editor to
// view it. This list provides the font reference number needed below to locate that
// font on your system.
// The sketch also lists all the available system fonts to the console, you can increase
// the console line count (in preferences.txt) to stop some fonts scrolling out of view.
// See link in File>Preferences to locate "preferences.txt" file. You must close
// Processing then edit the file lines. If Processing is not closed first then the
// edits will be overwritten by defaults! Edit "preferences.txt" as follows for
// 3000 lines, then save, then run Processing again:
// console.length=3000; // Line 4 in file
// console.scrollback.lines=3000; // Line 7 in file
// Useful links:
/*
https://en.wikipedia.org/wiki/Unicode_font
https://www.gnu.org/software/freefont/
https://www.gnu.org/software/freefont/sources/
https://www.gnu.org/software/freefont/ranges/
http://savannah.gnu.org/projects/freefont/
http://www.google.com/get/noto/
https://github.com/Bodmer/TFT_eSPI
https://github.com/esp8266/arduino-esp8266fs-plugin
https://github.com/me-no-dev/arduino-esp32fs-plugin
>>>>>>>>>>>>>>>>>>>> END OF INSTRUCTIONS <<<<<<<<<<<<<<<<<<<< */
import java.awt.Desktop; // Required to allow sketch to open file windows
////////////////////////////////////////////////////////////////////////////////////////////////
// >>>>>>>>>> USER CONFIGURED PARAMETERS START HERE <<<<<<<<<<
// Use font number or name, -1 for fontNumber means use fontName below, a value >=0 means use system font number from list.
// When the sketch is run it will generate a file called "systemFontList.txt" in the sketch folder, press Ctrl+K to see it.
// Open the "systemFontList.txt" in a text editor to view the font files and reference numbers for your system.
int fontNumber = -1; // << Use [Number] in brackets from the fonts listed.
// 或者使用放置在"Data"文件夹中的ttf文件的字体名称,或者在IDE控制台中看到的系统字体的字体编号
// 当草图运行时,会列出字体编号。
// | 1 2 | SPIFFS的最大文件名大小为31,包括前导/
// 1234567890123456789012345 以及添加的点大小和.vlw扩展名,所以最大为25
String fontName = "DingTalk-JinBuTi"; // 如果需要,创建后手动裁剪文件名长度
// 注意:SPIFFS不接受文件名中的下划线!
String fontType = ".ttf";
//String fontType = ".otf";
// 为TFT_eSPI字体文件定义字体大小(以点为单位)
int fontSize = 28;
// 在Processing草图显示窗口中使用的字体大小(可以与上面不同)
int displayFontSize = 28;
// 创建一个C头文件(.h文件),准备在使用或复制到草图文件夹时使用
boolean createHeaderFile = true;
// 完成后自动打开包含创建文件的文件夹
boolean openFolder = true;
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// Next we specify which unicode blocks from the the Basic Multilingual Plane (BMP) are included in the final font file. //
// Note: The ttf/otf font file MAY NOT contain all possible Unicode characters, refer to the fonts online documentation. //
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
static final int[] unicodeBlocks = {
// 以下列表是根据此处的表格创建的:https://en.wikipedia.org/wiki/Unicode_block
// 移除下面行首的//以包含该Unicode区块,也可以通过编辑起始和结束范围值来指定不同的代码范围。
// 可以包含下面列表中的多行,仅受最终字体文件大小的限制!
// 区块范围, //区块名称, 代码点, 已分配字符, 文字系统
// 起始, 结束, //范围包括起始和结束代码
0x0021, 0x007E, //Basic Latin, 128, 128, Latin (52 characters), Common (76 characters)
//0x0080, 0x00FF, //Latin-1 Supplement, 128, 128, Latin (64 characters), Common (64 characters)
//0x0100, 0x017F, //Latin Extended-A, 128, 128, Latin
//0x0180, 0x024F, //Latin Extended-B, 208, 208, Latin
//0x0250, 0x02AF, //IPA Extensions, 96, 96, Latin
//0x02B0, 0x02FF, //Spacing Modifier Letters, 80, 80, Bopomofo (2 characters), Latin (14 characters), Common (64 characters)
//0x0300, 0x036F, //Combining Diacritical Marks, 112, 112, Inherited
//0x0370, 0x03FF, //Greek and Coptic, 144, 135, Coptic (14 characters), Greek (117 characters), Common (4 characters)
//0x0400, 0x04FF, //Cyrillic, 256, 256, Cyrillic (254 characters), Inherited (2 characters)
//0x0500, 0x052F, //Cyrillic Supplement, 48, 48, Cyrillic
//0x0530, 0x058F, //Armenian, 96, 89, Armenian (88 characters), Common (1 character)
//0x0590, 0x05FF, //Hebrew, 112, 87, Hebrew
//0x0600, 0x06FF, //Arabic, 256, 255, Arabic (237 characters), Common (6 characters), Inherited (12 characters)
//0x0700, 0x074F, //Syriac, 80, 77, Syriac
//0x0750, 0x077F, //Arabic Supplement, 48, 48, Arabic
//0x0780, 0x07BF, //Thaana, 64, 50, Thaana
//0x07C0, 0x07FF, //NKo, 64, 59, Nko
//0x0800, 0x083F, //Samaritan, 64, 61, Samaritan
//0x0840, 0x085F, //Mandaic, 32, 29, Mandaic
//0x0860, 0x086F, //Syriac Supplement, 16, 11, Syriac
//0x08A0, 0x08FF, //Arabic Extended-A, 96, 73, Arabic (72 characters), Common (1 character)
//0x0900, 0x097F, //Devanagari, 128, 128, Devanagari (124 characters), Common (2 characters), Inherited (2 characters)
//0x0980, 0x09FF, //Bengali, 128, 95, Bengali
//0x0A00, 0x0A7F, //Gurmukhi, 128, 79, Gurmukhi
//0x0A80, 0x0AFF, //Gujarati, 128, 91, Gujarati
//0x0B00, 0x0B7F, //Oriya, 128, 90, Oriya
//0x0B80, 0x0BFF, //Tamil, 128, 72, Tamil
//0x0C00, 0x0C7F, //Telugu, 128, 96, Telugu
//0x0C80, 0x0CFF, //Kannada, 128, 88, Kannada
//0x0D00, 0x0D7F, //Malayalam, 128, 117, Malayalam
//0x0D80, 0x0DFF, //Sinhala, 128, 90, Sinhala
//0x0E00, 0x0E7F, //Thai, 128, 87, Thai (86 characters), Common (1 character)
//0x0E80, 0x0EFF, //Lao, 128, 67, Lao
//0x0F00, 0x0FFF, //Tibetan, 256, 211, Tibetan (207 characters), Common (4 characters)
//0x1000, 0x109F, //Myanmar, 160, 160, Myanmar
//0x10A0, 0x10FF, //Georgian, 96, 88, Georgian (87 characters), Common (1 character)
//0x1100, 0x11FF, //Hangul Jamo, 256, 256, Hangul
//0x1200, 0x137F, //Ethiopic, 384, 358, Ethiopic
//0x1380, 0x139F, //Ethiopic Supplement, 32, 26, Ethiopic
//0x13A0, 0x13FF, //Cherokee, 96, 92, Cherokee
//0x1400, 0x167F, //Unified Canadian Aboriginal Syllabics, 640, 640, Canadian Aboriginal
//0x1680, 0x169F, //Ogham, 32, 29, Ogham
//0x16A0, 0x16FF, //Runic, 96, 89, Runic (86 characters), Common (3 characters)
//0x1700, 0x171F, //Tagalog, 32, 20, Tagalog
//0x1720, 0x173F, //Hanunoo, 32, 23, Hanunoo (21 characters), Common (2 characters)
//0x1740, 0x175F, //Buhid, 32, 20, Buhid
//0x1760, 0x177F, //Tagbanwa, 32, 18, Tagbanwa
//0x1780, 0x17FF, //Khmer, 128, 114, Khmer
//0x1800, 0x18AF, //Mongolian, 176, 156, Mongolian (153 characters), Common (3 characters)
//0x18B0, 0x18FF, //Unified Canadian Aboriginal Syllabics Extended, 80, 70, Canadian Aboriginal
//0x1900, 0x194F, //Limbu, 80, 68, Limbu
//0x1950, 0x197F, //Tai Le, 48, 35, Tai Le
//0x1980, 0x19DF, //New Tai Lue, 96, 83, New Tai Lue
//0x19E0, 0x19FF, //Khmer Symbols, 32, 32, Khmer
//0x1A00, 0x1A1F, //Buginese, 32, 30, Buginese
//0x1A20, 0x1AAF, //Tai Tham, 144, 127, Tai Tham
//0x1AB0, 0x1AFF, //Combining Diacritical Marks Extended, 80, 15, Inherited
//0x1B00, 0x1B7F, //Balinese, 128, 121, Balinese
//0x1B80, 0x1BBF, //Sundanese, 64, 64, Sundanese
//0x1BC0, 0x1BFF, //Batak, 64, 56, Batak
//0x1C00, 0x1C4F, //Lepcha, 80, 74, Lepcha
//0x1C50, 0x1C7F, //Ol Chiki, 48, 48, Ol Chiki
//0x1C80, 0x1C8F, //Cyrillic Extended-C, 16, 9, Cyrillic
//0x1CC0, 0x1CCF, //Sundanese Supplement, 16, 8, Sundanese
//0x1CD0, 0x1CFF, //Vedic Extensions, 48, 42, Common (15 characters), Inherited (27 characters)
//0x1D00, 0x1D7F, //Phonetic Extensions, 128, 128, Cyrillic (2 characters), Greek (15 characters), Latin (111 characters)
//0x1D80, 0x1DBF, //Phonetic Extensions Supplement, 64, 64, Greek (1 character), Latin (63 characters)
//0x1DC0, 0x1DFF, //Combining Diacritical Marks Supplement, 64, 63, Inherited
//0x1E00, 0x1EFF, //Latin Extended Additional, 256, 256, Latin
//0x1F00, 0x1FFF, //Greek Extended, 256, 233, Greek
//0x2000, 0x206F, //General Punctuation, 112, 111, Common (109 characters), Inherited (2 characters)
//0x2070, 0x209F, //Superscripts and Subscripts, 48, 42, Latin (15 characters), Common (27 characters)
//0x20A0, 0x20CF, //Currency Symbols, 48, 32, Common
//0x20D0, 0x20FF, //Combining Diacritical Marks for Symbols, 48, 33, Inherited
//0x2100, 0x214F, //Letterlike Symbols, 80, 80, Greek (1 character), Latin (4 characters), Common (75 characters)
//0x2150, 0x218F, //Number Forms, 64, 60, Latin (41 characters), Common (19 characters)
//0x2190, 0x21FF, //Arrows, 112, 112, Common
//0x2200, 0x22FF, //Mathematical Operators, 256, 256, Common
//0x2300, 0x23FF, //Miscellaneous Technical, 256, 256, Common
//0x2400, 0x243F, //Control Pictures, 64, 39, Common
//0x2440, 0x245F, //Optical Character Recognition, 32, 11, Common
//0x2460, 0x24FF, //Enclosed Alphanumerics, 160, 160, Common
//0x2500, 0x257F, //Box Drawing, 128, 128, Common
//0x2580, 0x259F, //Block Elements, 32, 32, Common
//0x25A0, 0x25FF, //Geometric Shapes, 96, 96, Common
//0x2600, 0x26FF, //Miscellaneous Symbols, 256, 256, Common
//0x2700, 0x27BF, //Dingbats, 192, 192, Common
//0x27C0, 0x27EF, //Miscellaneous Mathematical Symbols-A, 48, 48, Common
//0x27F0, 0x27FF, //Supplemental Arrows-A, 16, 16, Common
//0x2800, 0x28FF, //Braille Patterns, 256, 256, Braille
//0x2900, 0x297F, //Supplemental Arrows-B, 128, 128, Common
//0x2980, 0x29FF, //Miscellaneous Mathematical Symbols-B, 128, 128, Common
//0x2A00, 0x2AFF, //Supplemental Mathematical Operators, 256, 256, Common
//0x2B00, 0x2BFF, //Miscellaneous Symbols and Arrows, 256, 207, Common
//0x2C00, 0x2C5F, //Glagolitic, 96, 94, Glagolitic
//0x2C60, 0x2C7F, //Latin Extended-C, 32, 32, Latin
//0x2C80, 0x2CFF, //Coptic, 128, 123, Coptic
//0x2D00, 0x2D2F, //Georgian Supplement, 48, 40, Georgian
//0x2D30, 0x2D7F, //Tifinagh, 80, 59, Tifinagh
//0x2D80, 0x2DDF, //Ethiopic Extended, 96, 79, Ethiopic
//0x2DE0, 0x2DFF, //Cyrillic Extended-A, 32, 32, Cyrillic
//0x2E00, 0x2E7F, //Supplemental Punctuation, 128, 74, Common
//0x2E80, 0x2EFF, //CJK Radicals Supplement, 128, 115, Han
//0x2F00, 0x2FDF, //Kangxi Radicals, 224, 214, Han
//0x2FF0, 0x2FFF, //Ideographic Description Characters, 16, 12, Common
//0x3000, 0x303F, //CJK Symbols and Punctuation, 64, 64, Han (15 characters), Hangul (2 characters), Common (43 characters), Inherited (4 characters)
//0x3040, 0x309F, //Hiragana, 96, 93, Hiragana (89 characters), Common (2 characters), Inherited (2 characters)
//0x30A0, 0x30FF, //Katakana, 96, 96, Katakana (93 characters), Common (3 characters)
//0x3100, 0x312F, //Bopomofo, 48, 42, Bopomofo
//0x3130, 0x318F, //Hangul Compatibility Jamo, 96, 94, Hangul
//0x3190, 0x319F, //Kanbun, 16, 16, Common
//0x31A0, 0x31BF, //Bopomofo Extended, 32, 27, Bopomofo
//0x31C0, 0x31EF, //CJK Strokes, 48, 36, Common
//0x31F0, 0x31FF, //Katakana Phonetic Extensions, 16, 16, Katakana
//0x3200, 0x32FF, //Enclosed CJK Letters and Months, 256, 254, Hangul (62 characters), Katakana (47 characters), Common (145 characters)
//0x3300, 0x33FF, //CJK Compatibility, 256, 256, Katakana (88 characters), Common (168 characters)
//0x3400, 0x4DBF, //CJK Unified Ideographs Extension A, 6,592, 6,582, Han
//0x4DC0, 0x4DFF, //Yijing Hexagram Symbols, 64, 64, Common
//0x4E00, 0x9FFF, //CJK Unified Ideographs, 20,992, 20,971, Han
//0xA000, 0xA48F, //Yi Syllables, 1,168, 1,165, Yi
//0xA490, 0xA4CF, //Yi Radicals, 64, 55, Yi
//0xA4D0, 0xA4FF, //Lisu, 48, 48, Lisu
//0xA500, 0xA63F, //Vai, 320, 300, Vai
//0xA640, 0xA69F, //Cyrillic Extended-B, 96, 96, Cyrillic
//0xA6A0, 0xA6FF, //Bamum, 96, 88, Bamum
//0xA700, 0xA71F, //Modifier Tone Letters, 32, 32, Common
//0xA720, 0xA7FF, //Latin Extended-D, 224, 160, Latin (155 characters), Common (5 characters)
//0xA800, 0xA82F, //Syloti Nagri, 48, 44, Syloti Nagri
//0xA830, 0xA83F, //Common Indic Number Forms, 16, 10, Common
//0xA840, 0xA87F, //Phags-pa, 64, 56, Phags Pa
//0xA880, 0xA8DF, //Saurashtra, 96, 82, Saurashtra
//0xA8E0, 0xA8FF, //Devanagari Extended, 32, 30, Devanagari
//0xA900, 0xA92F, //Kayah Li, 48, 48, Kayah Li (47 characters), Common (1 character)
//0xA930, 0xA95F, //Rejang, 48, 37, Rejang
//0xA960, 0xA97F, //Hangul Jamo Extended-A, 32, 29, Hangul
//0xA980, 0xA9DF, //Javanese, 96, 91, Javanese (90 characters), Common (1 character)
//0xA9E0, 0xA9FF, //Myanmar Extended-B, 32, 31, Myanmar
//0xAA00, 0xAA5F, //Cham, 96, 83, Cham
//0xAA60, 0xAA7F, //Myanmar Extended-A, 32, 32, Myanmar
//0xAA80, 0xAADF, //Tai Viet, 96, 72, Tai Viet
//0xAAE0, 0xAAFF, //Meetei Mayek Extensions, 32, 23, Meetei Mayek
//0xAB00, 0xAB2F, //Ethiopic Extended-A, 48, 32, Ethiopic
//0xAB30, 0xAB6F, //Latin Extended-E, 64, 54, Latin (52 characters), Greek (1 character), Common (1 character)
//0xAB70, 0xABBF, //Cherokee Supplement, 80, 80, Cherokee
//0xABC0, 0xABFF, //Meetei Mayek, 64, 56, Meetei Mayek
//0xAC00, 0xD7AF, //Hangul Syllables, 11,184, 11,172, Hangul
//0xD7B0, 0xD7FF, //Hangul Jamo Extended-B, 80, 72, Hangul
//0xD800, 0xDB7F, //High Surrogates, 896, 0, Unknown
//0xDB80, 0xDBFF, //High Private Use Surrogates, 128, 0, Unknown
//0xDC00, 0xDFFF, //Low Surrogates, 1,024, 0, Unknown
//0xE000, 0xF8FF, //Private Use Area, 6,400, 6,400, Unknown
//0xF900, 0xFAFF, //CJK Compatibility Ideographs, 512, 472, Han
//0xFB00, 0xFB4F, //Alphabetic Presentation Forms, 80, 58, Armenian (5 characters), Hebrew (46 characters), Latin (7 characters)
//0xFB50, 0xFDFF, //Arabic Presentation Forms-A, 688, 611, Arabic (609 characters), Common (2 characters)
//0xFE00, 0xFE0F, //Variation Selectors, 16, 16, Inherited
//0xFE10, 0xFE1F, //Vertical Forms, 16, 10, Common
//0xFE20, 0xFE2F, //Combining Half Marks, 16, 16, Cyrillic (2 characters), Inherited (14 characters)
//0xFE30, 0xFE4F, //CJK Compatibility Forms, 32, 32, Common
//0xFE50, 0xFE6F, //Small Form Variants, 32, 26, Common
//0xFE70, 0xFEFF, //Arabic Presentation Forms-B, 144, 141, Arabic (140 characters), Common (1 character)
//0xFF00, 0xFFEF, //Halfwidth and Fullwidth Forms, 240, 225, Hangul (52 characters), Katakana (55 characters), Latin (52 characters), Common (66 characters)
//0xFFF0, 0xFFFF, //Specials, 16, 5, Common
//0x0030, 0x0039, //Example custom range (numbers 0-9)
//0x0041, 0x005A, //Example custom range (Upper case A-Z)
//0x0061, 0x007A, //Example custom range (Lower case a-z)
};
// 在此处我们指定要包含的特定单个Unicode(附加在所选范围的末尾)
static final int[] specificUnicodes = {
0x4f60,0x597d,0x4e16,0x754c
// 常用代码,在下一行中添加或移除//
// 0x00A3, 0x00B0, 0x00B5, 0x03A9, 0x20AC, // £ ° µ Ω €
// 显示时间所用的数字和字符,将下一行更改为//*以使用
/*
0x002B, 0x002D, 0x002E, 0x0030, 0x0031, 0x0032, 0x0033, 0x0034, // - + . 0 1 2 3 4
0x0035, 0x0036, 0x0037, 0x0038, 0x0039, 0x003A, 0x0061, 0x006D, // 5 6 7 8 9 : a m
0x0070, // p
//*/
// More characters for TFT_eSPI test sketches, change next line to //* to use
/*
0x0102, 0x0103, 0x0104, 0x0105, 0x0106, 0x0107, 0x010C, 0x010D,
0x010E, 0x010F, 0x0110, 0x0111, 0x0118, 0x0119, 0x011A, 0x011B,
0x0131, 0x0139, 0x013A, 0x013D, 0x013E, 0x0141, 0x0142, 0x0143,
0x0144, 0x0147, 0x0148, 0x0150, 0x0151, 0x0152, 0x0153, 0x0154,
0x0155, 0x0158, 0x0159, 0x015A, 0x015B, 0x015E, 0x015F, 0x0160,
0x0161, 0x0162, 0x0163, 0x0164, 0x0165, 0x016E, 0x016F, 0x0170,
0x0171, 0x0178, 0x0179, 0x017A, 0x017B, 0x017C, 0x017D, 0x017E,
0x0192,
0x02C6, 0x02C7, 0x02D8, 0x02D9, 0x02DA, 0x02DB, 0x02DC, 0x02DD,
0x03A9, 0x03C0, 0x2013, 0x2014, 0x2018, 0x2019, 0x201A, 0x201C,
0x201D, 0x201E, 0x2020, 0x2021, 0x2022, 0x2026, 0x2030, 0x2039,
0x203A, 0x2044, 0x20AC,
0x2122, 0x2202, 0x2206, 0x220F,
0x2211, 0x221A, 0x221E, 0x222B, 0x2248, 0x2260, 0x2264, 0x2265,
0x25CA,
0xF8FF, 0xFB01, 0xFB02,
//*/
};
// >>>>>>>>>> USER CONFIGURED PARAMETERS END HERE <<<<<<<<<<
////////////////////////////////////////////////////////////////////////////////////////////////
// Variable to hold the inclusive Unicode range (16-bit values only for this sketch)
int firstUnicode = 0;
int lastUnicode = 0;
PFont myFont;
PrintWriter logOutput;
void setup() {
logOutput = createWriter("FontFiles/System_Font_List.txt");
size(1000, 800);
// Print the available fonts to the console as a list:
String[] fontList = PFont.list();
printArray(fontList);
// Save font list to file
for (int x = 0; x < fontList.length; x++)
{
logOutput.print("[" + x + "] ");
logOutput.println(fontList[x]);
}
logOutput.flush(); // Writes the remaining data to the file
logOutput.close(); // Finishes the file
// Set the fontName from the array number or the defined fontName
if (fontNumber >= 0)
{
// fontName = fontList[fontNumber];
fontType = "";
}
char[] charset;
int index = 0, count = 0;
int blockCount = unicodeBlocks.length;
for (int i = 0; i < blockCount; i+=2) {
firstUnicode = unicodeBlocks[i];
lastUnicode = unicodeBlocks[i+1];
if (lastUnicode < firstUnicode) {
delay(100);
System.err.println("ERROR: Bad Unicode range secified, last < first!");
System.err.print("first in range = 0x" + hex(firstUnicode, 4));
System.err.println(", last in range = 0x" + hex(lastUnicode, 4));
while (true);
}
// calculate the number of characters
count += (lastUnicode - firstUnicode + 1);
}
count += specificUnicodes.length;
println();
println("=====================");
println("Creating font file...");
println("Unicode blocks included = " + (blockCount/2));
println("Specific unicodes included = " + specificUnicodes.length);
println("Total number of characters = " + count);
if (count == 0) {
delay(100);
System.err.println("ERROR: No Unicode range or specific codes have been defined!");
while (true);
}
// allocate memory
charset = new char[count];
for (int i = 0; i < blockCount; i+=2) {
firstUnicode = unicodeBlocks[i];
lastUnicode = unicodeBlocks[i+1];
// loading the range specified
for (int code = firstUnicode; code <= lastUnicode; code++) {
charset[index] = Character.toChars(code)[0];
index++;
}
}
// loading the specific point codes
for (int i = 0; i < specificUnicodes.length; i++) {
charset[index] = Character.toChars(specificUnicodes[i])[0];
index++;
}
// Make font smooth (anti-aliased)
boolean smooth = true;
// Create the font in memory
myFont = createFont(fontName+fontType, displayFontSize, smooth, charset);
// Print characters to the sketch window
fill(0, 0, 0);
textFont(myFont);
// Set the left and top margin
int margin = displayFontSize;
translate(margin/2, margin);
int gapx = displayFontSize*10/8;
int gapy = displayFontSize*10/8;
index = 0;
fill(0);
textSize(displayFontSize);
for (int y = 0; y < height-gapy; y += gapy) {
int x = 0;
while (x < width) {
int unicode = charset[index];
float cwidth = textWidth((char)unicode) + 2;
if ( (x + cwidth) > (width - gapx) ) break;
// Draw the glyph to the screen
text(new String(Character.toChars(unicode)), x, y);
// Move cursor
x += cwidth;
// Increment the counter
index++;
if (index >= count) break;
}
if (index >= count) break;
}
// creating font to save as a file
PFont font;
font = createFont(fontName+fontType, fontSize, smooth, charset);
println("Created font " + fontName + str(fontSize) + ".vlw");
String fontFileName = "FontFiles/" + fontName + str(fontSize) + ".vlw";
// creating file
try {
print("Saving to sketch FontFiles folder... ");
OutputStream output = createOutput(fontFileName);
font.save(output);
output.close();
println("OK!");
delay(100);
// Open up the FontFiles folder to access the saved file
String path = sketchPath();
if(openFolder){
Desktop.getDesktop().open(new File(path+"/FontFiles"));
}
System.err.println("All done! Note: Rectangles are displayed for non-existant characters.");
}
catch(IOException e) {
println("Doh! Failed to create the file");
}
if(!createHeaderFile) return;
// Now creating header file if the option was specified.
try{
print("saving header file to FontFile folder...");
InputStream input = createInputRaw(fontFileName);
PrintWriter output = createWriter("FontFiles/" + fontName + str(fontSize) + ".h");
output.println("#include <pgmspace.h>");
output.println();
output.println("const uint8_t " + fontName + str(fontSize) + "[] PROGMEM = {");
int i = 0;
int data = input.read();
while(data != -1){
output.print("0x");
output.print(hex(data, 2));
if(i++ < 15){
output.print(", ");
} else {
output.println(",");
i = 0;
}
data = input.read();
}
// font.save(output);
output.println("\n};");
output.close();
input.close();
println("C header file created.");
} catch(IOException e){
println("Failed to create C header file");
}
}