(一)使用协程池原因分析 🔗
Go协程的创建到运行结束,所占用的内存资源都是需要通过GC来回收,如果没有限制的创造海量的Go协程后,会增加GC的压力。创建的Go协程越多,GC压力越大耗时也越大。
使用work池的优点:
- 减少获取
goroutine的成本,减轻硬件资源负担。 - 可以限制并发数,让系统运行在一个可控的环境下。
- 在有大量长连接时,把逻辑处理丢给协程池,减少栈扩容,把栈扩容限定在协程池的协程中,减少GC压力。
(二)协程池的实现 🔗
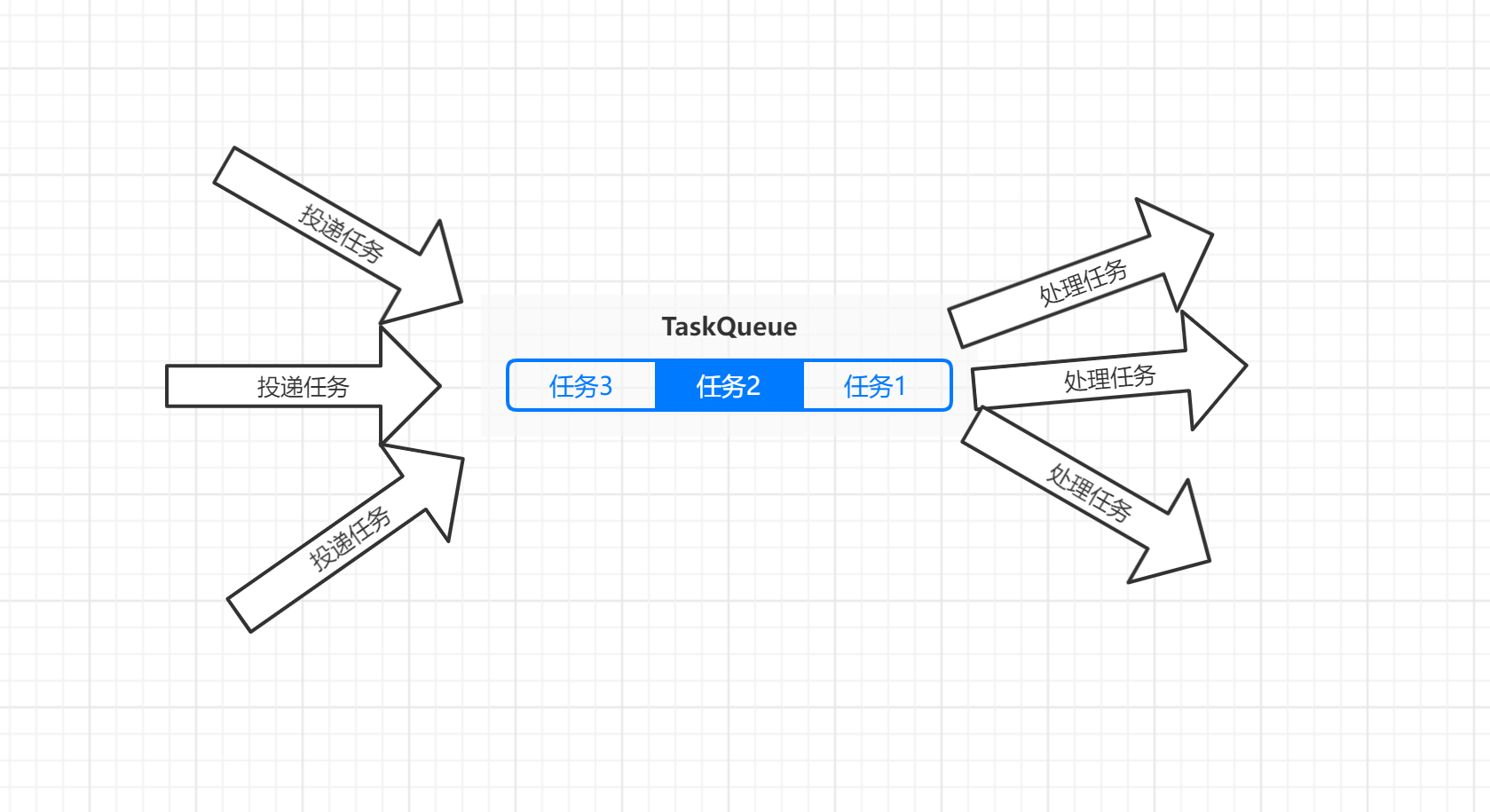
操作任务池的goroutine作为生产者不断的将任务投递到队列中,真实用来处理逻辑的goroutine作为消费者从队列中取出任务处理,使用通道channel来作为队列,生产者的任务投递到channel中。
生产者(投递任务)–> 任务队列–> 消费者(消费任务)
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type Pool struct {
pool []chan *SendData
}
var (
MaxPool = 10 //消费者最大数量
capacity = 2 //队列容量
Wg sync.WaitGroup
WgSendData sync.WaitGroup
)
func NewPool() *Pool {
return &Pool{pool: make([]chan *SendData, MaxPool)}
}
// 生成工作work
func (p *Pool) startPool() {
for i := 0; i < MaxPool; i++ {
p.pool[i] = make(chan *SendData, capacity)
go p.startOneWork(i, p.pool[i])
}
}
// 创建工作work
func (p *Pool) startOneWork(workerID int, taskQueue chan *SendData) {
fmt.Println("Worker ID = ", workerID, " is started.")
Wg.Done()
//不断的等待队列中的消息
for {
select {
//有消息则取出队列的Request,并执行绑定的业务方法
case request := <-taskQueue:
fmt.Printf("接收到的任务信息:workdId:%d,数据:%d\n", workerID, request.Data)
time.Sleep(1 * time.Second)
WgSendData.Done()
}
}
}
type SendData struct {
Data int
}
// 生产者
func (p *Pool) SendToWork(data *SendData) {
i := rand.Intn(9)
p.pool[i] <- data
}
func main() {
Wg.Add(MaxPool)
pool := NewPool()
pool.startPool()
Wg.Wait()
for i := 0; i <= 100; i++ {
WgSendData.Add(1)
//生产者,投递任务
pool.SendToWork(&SendData{
Data: i,
})
}
WgSendData.Wait()
}
(三)GPM调度模型简介 🔗
groutine能拥有强大的并发实现是通过 GPM 调度模型实现,下面就来解释下groutine的调度模型。
Go 的调度器内部有四个重要的结构:M,P,S,Sched
- M:M 代表内核级线程,一个 M 就是一个线程,
groutine就是跑在 M 之上的;M 是一个很大的结构,里面维护小对象内存 cache。(mcache)、当前执行的groutine、随机数发生器等等非常多的信息 - G: 代表一个
groutine,它有自己的栈,instruction pointer 和其他信息(正在等待的 channel 等等),用于调度。 - P:P 全称是 Processor,处理器,它的主要用途就是用来执行
groutine的,所以它也维护了一个groutine队列,里面存储了所有需要它来执行的groutine。 - Sched:代表调度器,它维护有存储 M 和 G 的队列以及调度器的一些状态信息等。
(四)协程的优点和缺点 🔗
1.协程的优点 🔗
- 占用小:协程更加轻量,创建成本更小,降低了内存消耗,协程一般只占据极小的内存(2~5KB),而线城市1MB左右。虽然线程和协程都是独有栈,但是线程栈是固定的,比如在Java中,基本是2M,假如一个栈只有一个打印方法,还要为此开辟一个2M的栈,就太浪费了。而Go的的协程具备动态收缩功能,初始化为2KB,最大可达1GB
- 运行效率高:线程切换需要从用户态->内核态->用户态,而协程切换是在用户态上,即用户态->用户态->用户态,其切换过程由语言层面的调度器(coroutine)或者语言引擎(goroutine)实现。
- 减少了同步锁:协程最终还是运行在线程上,本质上还是单线程运行,没有临界区域的话自然不需要锁的机制。多协程自然没有竞争关系。但是,如果存在临界区域,依然需要使用锁,协程可以减少以往必须使用锁的场景
- 同步代码思维写出异步代码
2.协程的缺点 🔗
- 无法利用多核资源:协程运行在线程上,单线程应用无法很好的利用多核,只能以多进程方式启动。
- 协程不能有阻塞操作:线程是抢占式,线程在遇见IO操作时候,线程从运行态→阻塞态,释放cpu使用权。这是由操作系统调度。协程是非抢占式,如果遇见IO操作时候,协程是主动释放执行权限的,如果无法主动释放,程序将阻塞,无法往下执行,随之而来是整个线程被阻塞。
- CPU密集型不是长处:假设这个线程中有一个协程是 CPU 密集型的他没有 IO 操作,也就是自己不会主动触发调度器调度的过程,那么就会出现其他协程得不到执行的情况,所以这种情况下需要程序员自己避免。