问题 🔗
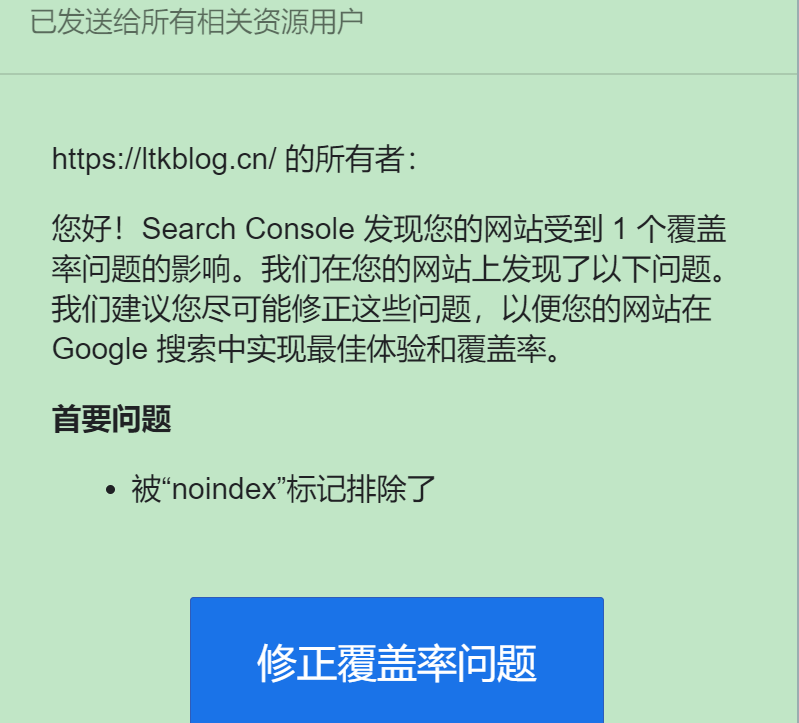
向Google提交了站点地图,今天收到Google发送的消息,显示网站被标记了noindex没有被搜索引擎收录。如下:
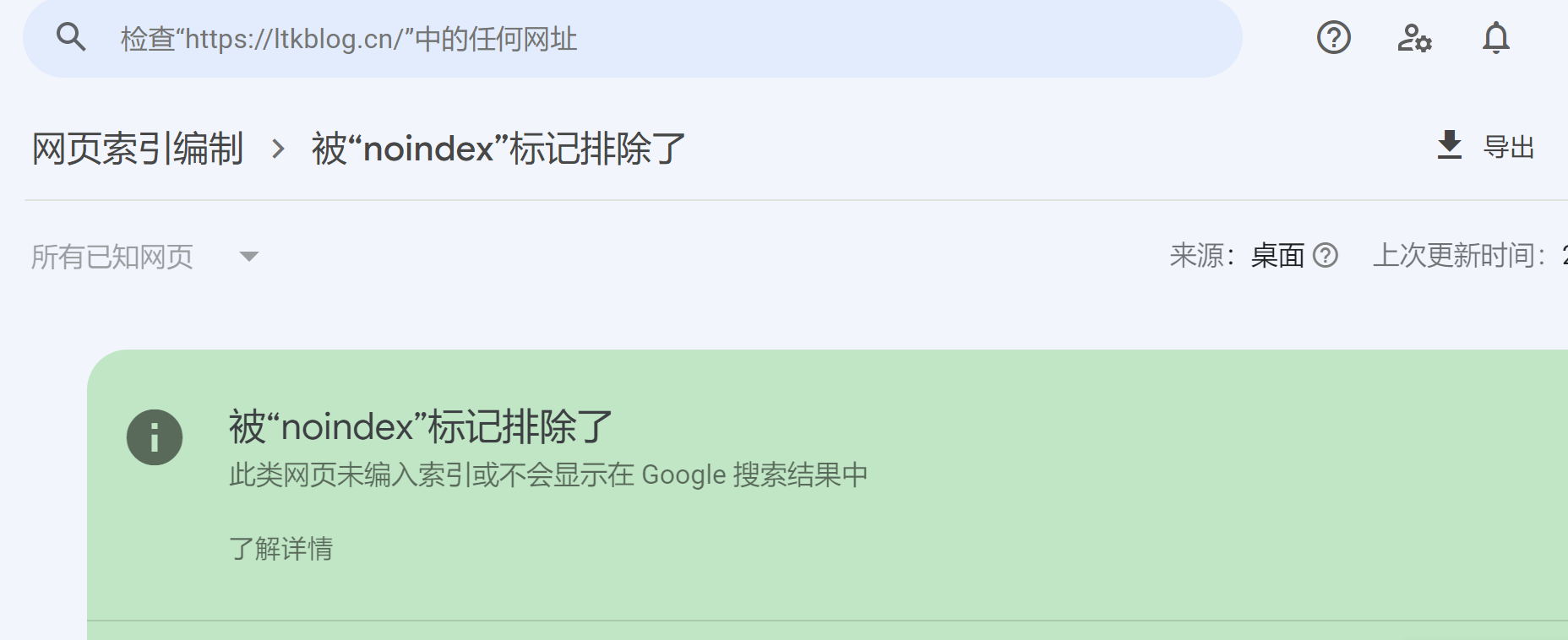
查询Google的开发文档大概意思如下:
- 网址遭到 robots.txt 阻止
此网页被网站的 robots.txt 文件屏蔽了。您可以使用 robots.txt 测试工具检查是否确实存在此情况。请注意,这并不意味着该网页不会被通过某些其他方式编入索引。如果 Google 不必加载该网页就能找到与它相关的其他信息,那么该网页仍然可能会被编入索引(尽管这种情况不太常见)。为确保 Google 不会将该网页编入索引,请移除 robots.txt 中的屏蔽指令,然后改用“noindex”指令。
- 网址已提交,但带有“noindex”标记
Google 在尝试将网页编入索引时遇到了“noindex”指令,因此未将该网页编入索引。如果您确实不希望该网页被编入索引,那么恭喜您得偿所愿!如果您希望该网页被编入索引,您应移除该“noindex”指令。如要确认此标记或指令是否存在,请在浏览器中请求该网页,并在响应正文和响应标头中搜索“noindex”。如果您想将该网页编入索引,必须移除相关的标记或 HTTP 标头。请使用网址检查工具来确认此错误,步骤如下:
- 点击表格中相应网址旁边的“检查”图标 。
- 在覆盖率 > 编制索引 > 是否允许编入索引?下,报告应表明是 noindex 在阻止系统将该网页编入索引。
- 确认实际版本中是否仍有 noindex 标记:
- 点击测试实际网址
- 在可否编入索引 > 编制索引 > 是否允许编入索引?下,查看是否仍会检测到 noindex 指令。如果 noindex 指令已不复存在,您可点击请求编入索引以请求 Google 再次尝试将该网页编入索引。如果 noindex 指令仍然存在,必须先移除它,然后才能将该网页编入索引。
原因 🔗
- 检查网站的
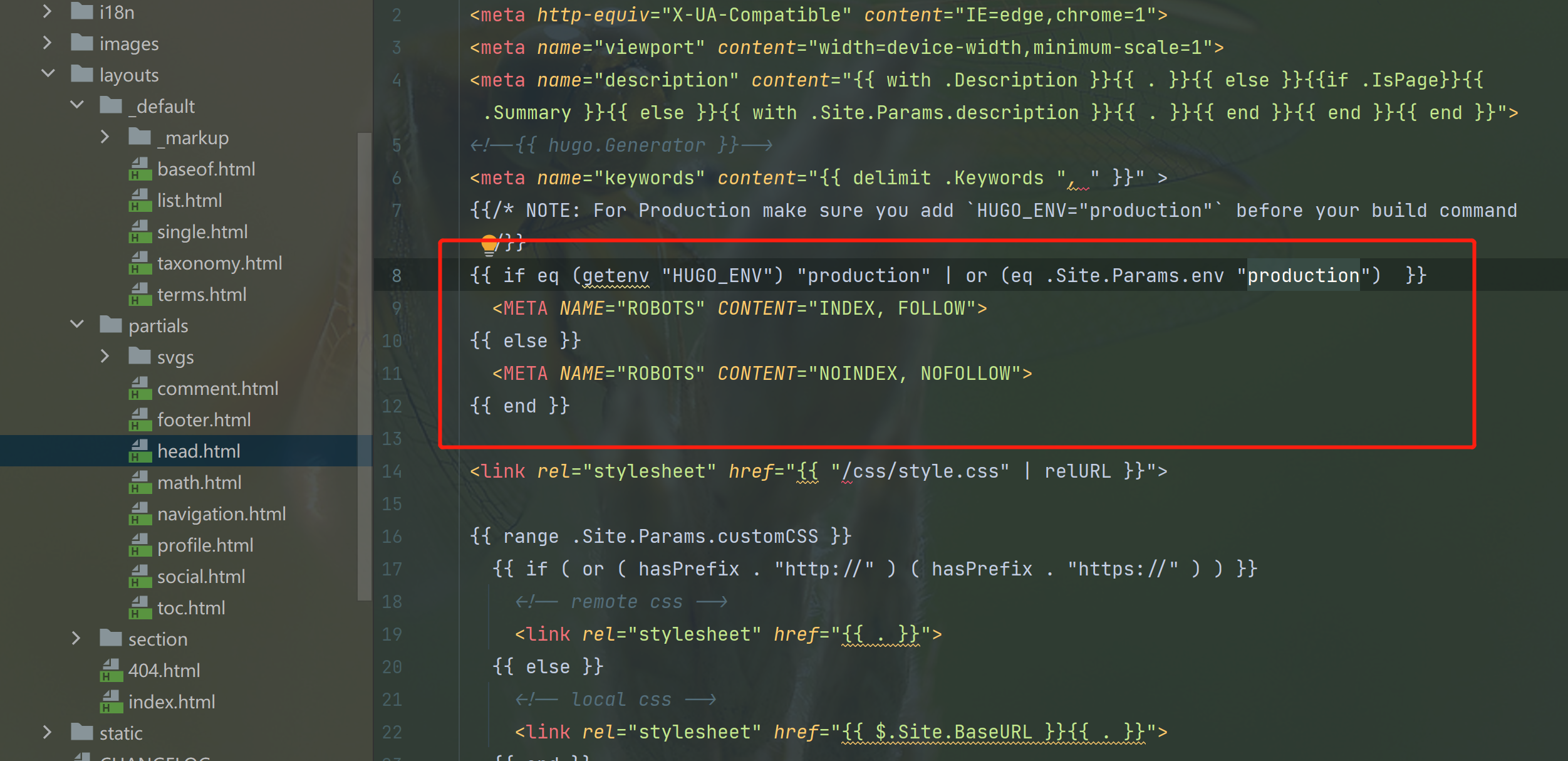
robots.txt文件是否有阻止爬虫收录。 - 检查
html文件中是否带有noindex、nofollow 标记:<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
解决 🔗
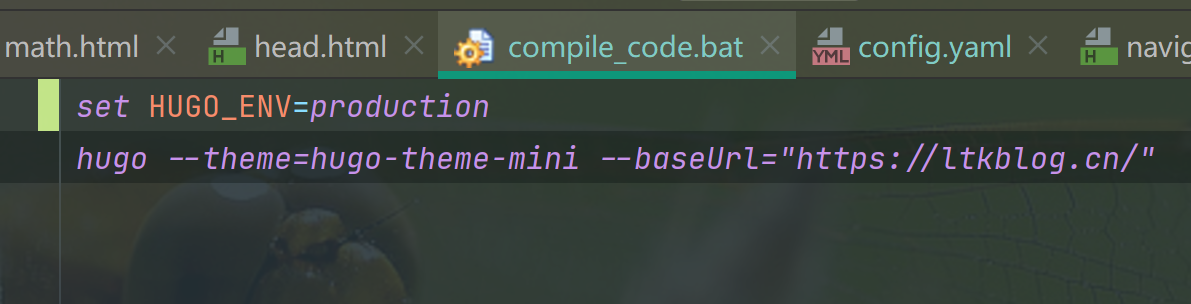
查看源码发现线上版本没有设置生产环境set HUGO_ENV=production
Windows编译时增加set HUGO_ENV=production即可。
再次查看源码发现问题解决,变成搜索引擎爬虫可以爬取。
注:其它系统使用HUGO_ENV=production hugo